






工業(yè)互聯網“咖”解丨江小涓:數據的經濟學分析:要素、產業(yè)和市場

數據的經濟學分析:要素、產業(yè)和市場
文/江小涓
中國社會科學院大學教授、國務院原副秘書長
去年以來,數據是一個很熱的熱點,從經濟學的角度需要一個很好的分析框架,因為經濟學中的生產要素分析是一個非常成熟的體系。我們現在把數據當成生產要素,這對經濟學界的理論提出了很大的挑戰(zhàn),我們來探討研究什么問題,才能稱之為學術研究。中國是首個把數據作為生產要素的國家,這在國際上是沒有先例的。作為一種生產要素,確權、交易、收益等概念需要納入分析框架中;作為一個產業(yè),產業(yè)組織、生產消費、價格形成等概念需要納入分析框架中;作為一個市場,創(chuàng)新、競爭、公共品等概念需要納入分析框架中。考慮到數據的特點,還需要在分析中擴展框架和增加維度。并且,研究方向要呼應經濟學的宗旨:研究社會資源配置的總體效率并盡可能合理分配。總之學術研究應該致力于知識體系的構建和完善。當下關于數據要素市場的研究,比較集中在數據確權、定價、交易等領域,希望學術界整體在數據研究方面繼續(xù)加強學術含量高的研究,來促進理論發(fā)展,服務實踐,促進國際交流,這是過去一年多我在參與數據問題時非常深切的體會。從經濟學視角思考,數據研究涉及非常多的學術問題:數據作為要素,配置效率怎么樣,比如確權、交易和收益的制度安排,最終希望配置的效率最高;數據作為產業(yè),需要研究具體經濟主體的行為及其市場影響,例如消費者和生產者行為、均衡價格、創(chuàng)新行為等;數據作為市場,要研究數據市場的規(guī)則、行為和結構,特別是AI出現以后的巨型企業(yè),對競爭規(guī)則、壟斷的判定,政府的規(guī)制該怎么做,是非常具有挑戰(zhàn)的問題;數據作為半公共品,公共利益和市場效益如何權衡,政府供給和市場供給的組合怎么判斷。
接下來舉例來講,數據要素我以確權、流通和收益為例,數據產業(yè)我用創(chuàng)新范式的改變作為例子,數據市場我們用規(guī)模遞增下的競爭和壟斷作為例子,公共數據以免費開發(fā)和收費開發(fā)的平衡作例子。
關于數據要素
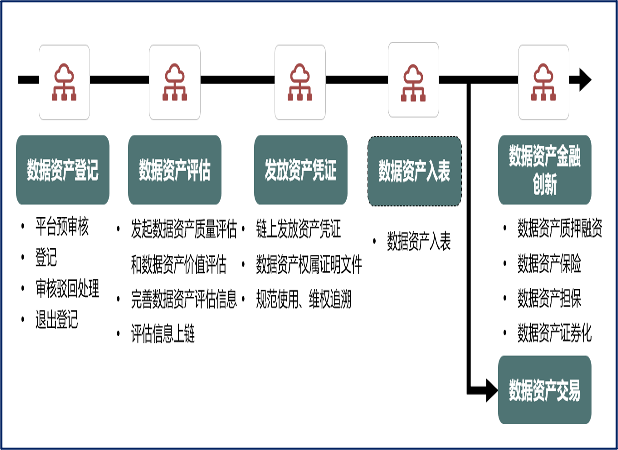
數據是一個生產要素,又是一個非常特別的要素,面臨的理論挑戰(zhàn)非常多。數據的獨特性質主要體現在以下幾個方面:首先是多主體生產因而確權困難,數據的生成過程錯綜復雜,常常是多方主體相互協作的結果,包含了不同主體不同程度的投入和貢獻,因此確權困難。其次是多場景復用方便,一組數據可以被不同主體以不同方式重復利用,在使用上不具有競爭性和排他性,不易清晰明確主張權力。第三是數據中的敏感信息多,許多數據的內容多層次多元化,可能承載了需要保護的個人信息和商業(yè)機密,即使匿名化和去標識化,也有可能被挖掘出來。第四是減損貶值快,絕大部分數據的價值在于實時性,有研究表明一年期以上的數據貶值達到 98% 以上,保值增值十分困難。各位想想,你經常點什么外賣,搜索過什么類型的服務、APP 就會推薦推送給你相關的內容,這都是從即時數據中挖掘到的,幾個月后可能你的口味發(fā)生了變化,按照現在數據推送就沒有意義。第五是具有交易和交互兩類流通方式,特別是交互型流動即數據在不同主體間的非交易型流通使用,與其他生產要素流通使用的形態(tài)相比有顯著不同。這個是我們后面要分析的重點問題。考慮到上述問題,在“數據二十條”的起草制定中,針對數據要素這些與其他生產要素不同的特點,文件的重點是構建起主要架構,即所謂的“四梁八柱”,許多更具體的內容都需要不斷探索發(fā)展,并從社會有較多共識、實踐有迫切需求、符合數據要素特征、與理論體系有較好契合性這些角度排出工作的重點。例如,在起步階段不回避“所有權”,但更強調持有權、使用權、經營權,讓數據先動起來用起來,就是現階段中國特色數據產權制度的一個鮮明特點。再如,處理好場內交易和場外交易的關系也是現實針對性很強的問題。從實踐看,數據流通使用既有通過數據交易所完成的“場內交易”,也有企業(yè)與企業(yè)之間直接發(fā)生“場外交易”,更有規(guī)模巨大的非交易型的數據交互。因此“數據二十條”并未強調以哪種流通方式為主,而是提出場內交易與場外交易相結合,不斷探索創(chuàng)新。在公共數據開放共享和開發(fā)利用、構建安全貫穿數據治理全過程的安全治理模式等方面,也都從理論與實踐的結合出發(fā),既提出長遠發(fā)展方向,也明確當下工作重點。 理解了數據要素的特點,就能理解一年多來數據要素市場發(fā)展中的困難與問題。數據要素交易所在“數據二十條”出臺前后特別是以后快速增長,但大體上是一個有市無價,或者有市有價無交易的情況,這在其他要素市場上很難看到。各地數據交易所發(fā)展很快,到 2023 年 10 月已經超過 48 家。每個交易所都有成千上萬家的數據服務商,也有些入場準備參與確權交易的數據供應方。但一年多下來(有些起步早的交易所嘗試時間更長,有些已有十年之久)數據交易量非常少,整體上仍在嘗試性起步階段。其實許多數據持有者都明白,數據交易很不容易,那他們?yōu)槭裁捶e極“入場”呢?企業(yè)期待數據入表,將數據資產化,進而能夠去做金融創(chuàng)新、融資擔保或資產證券化等。下圖是各個數據交易所表達自己平臺能夠做什么的邏輯:做數據資產登記、數據資產評估;然后發(fā)放數據資產憑證,進而入表;入表后的主線是去做金融創(chuàng)新、融資貸款等,其次是進行數據資產的交易。我和銀行開玩笑,說“數據要素市場建設發(fā)展的接力棒交到了金融領域,你們遲遲不接棒”。金融業(yè)不敢往下做的原因之一,就是認為數據資產定價、交易方式特別是易貶損特點帶來的挑戰(zhàn)和風險都是新問題,需要積極而謹慎,發(fā)展與安全并重。不過,雖然我們將數據納入傳統(tǒng)生產要素分析框架中有困難,但這是一個新事物,需要留給創(chuàng)新足夠的時間和空間。而且我們不一定要將其“裝”進我們熟悉的體系構建中間去,要允許探索。但從學術理論角度看,總要構建一個學術體系出來,這是一個非常有創(chuàng)新意義也有挑戰(zhàn)的領域。
理解了數據要素的特點,就能理解一年多來數據要素市場發(fā)展中的困難與問題。數據要素交易所在“數據二十條”出臺前后特別是以后快速增長,但大體上是一個有市無價,或者有市有價無交易的情況,這在其他要素市場上很難看到。各地數據交易所發(fā)展很快,到 2023 年 10 月已經超過 48 家。每個交易所都有成千上萬家的數據服務商,也有些入場準備參與確權交易的數據供應方。但一年多下來(有些起步早的交易所嘗試時間更長,有些已有十年之久)數據交易量非常少,整體上仍在嘗試性起步階段。其實許多數據持有者都明白,數據交易很不容易,那他們?yōu)槭裁捶e極“入場”呢?企業(yè)期待數據入表,將數據資產化,進而能夠去做金融創(chuàng)新、融資擔保或資產證券化等。下圖是各個數據交易所表達自己平臺能夠做什么的邏輯:做數據資產登記、數據資產評估;然后發(fā)放數據資產憑證,進而入表;入表后的主線是去做金融創(chuàng)新、融資貸款等,其次是進行數據資產的交易。我和銀行開玩笑,說“數據要素市場建設發(fā)展的接力棒交到了金融領域,你們遲遲不接棒”。金融業(yè)不敢往下做的原因之一,就是認為數據資產定價、交易方式特別是易貶損特點帶來的挑戰(zhàn)和風險都是新問題,需要積極而謹慎,發(fā)展與安全并重。不過,雖然我們將數據納入傳統(tǒng)生產要素分析框架中有困難,但這是一個新事物,需要留給創(chuàng)新足夠的時間和空間。而且我們不一定要將其“裝”進我們熟悉的體系構建中間去,要允許探索。但從學術理論角度看,總要構建一個學術體系出來,這是一個非常有創(chuàng)新意義也有挑戰(zhàn)的領域。
關于數據產業(yè)
數據產業(yè)鏈條中,各環(huán)節(jié)參與方的行為和以往不一樣,這個方面要研究的新問題很多。因為最近我在做一項數字時代創(chuàng)新問題研究,就拿它舉例。現在數據創(chuàng)新范式按照國內外的很多學者來說,進入了“數據密集型”的科研創(chuàng)新范式。我們能看到除了數字行業(yè)自身以外,生物醫(yī)學、高能物理、地球科學、海洋科學很多都是以信息科學為支撐的基礎研究領域,如果數據觀測處理能力不高,它們的進展是非常困難的。生命科學中,蛋白質怎么預測出來,不是生命科學自身的原創(chuàng)性發(fā)現,而是數字技術應用帶來的結果,其中的原理早就知道,但就是算不出來。現在,世界進入數字時代,數字技術迅速發(fā)展和海量數據的產生不僅顯著影響經濟社會運行方式,而且推動著科研范式的深刻變革。這種變革不是原來創(chuàng)新范式內部因素和結構的調整,而是“數據”這個新要素和數據復雜交互形成的“數據關系”這些新變量加入所引發(fā)的創(chuàng)新要素、創(chuàng)新主體和創(chuàng)新組織的深刻變革。

我們現在講到數據和數據關系,不光是數據量多少,主要是數據關系影響了創(chuàng)新的重要維度。我們現在 AI 發(fā)展相對滯后有很多原因,能夠共享的信息的數量和質量比較差,是影響下一步人工智能非常重要的因素。數據和算力決定誰來創(chuàng)新,包括很重要的原始創(chuàng)新。大模型的訓練和調整需要極其巨大的數據、算力和算法的投入,Transformer 架構進入主流以后,AI 算力每兩年增長 275 倍,在計算機本身有革命性的變革之前,只能靠擴量來增強算法的能力,所以目前只有大科技企業(yè)有雄厚的財力足以吸引大批頂尖的 AI 人才,從而以算力、算法和數據的最佳結合來推動人工智能前沿的突破,這就是最領先的 AI 大模型的變化。

如下圖,2014 年是一個轉折點,AI 系統(tǒng)不是高校研發(fā)后的產業(yè)轉化,而是從最基本的數學算法開始,都由產業(yè)界來做,2023 年 32 個重要的機器學習模型都誕生在產業(yè)界。我們現在也經常講國家創(chuàng)新體系,集中力量辦大事,這方面也要考慮到數字時代的這種產業(yè)創(chuàng)新范式變革。這種海量的算力、數據以及人才迅速決策的能力、技術迭代的速度,完全是另外一種創(chuàng)新的組織架構,其中的變化是非常重要的。

關于數據市場
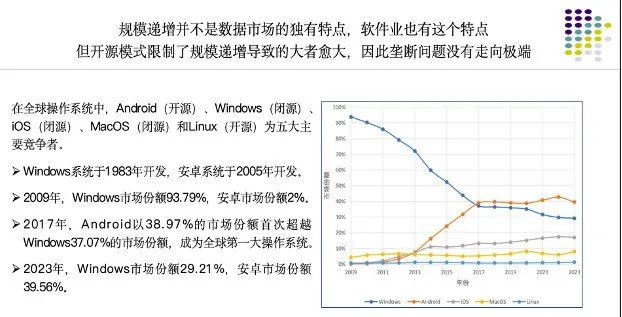
看待數據市場,需要研究市場的規(guī)則、行為和結構,特別是 AI 出現以后的“小規(guī)模企業(yè)+巨大市場”是非常具有挑戰(zhàn)的問題,對規(guī)模遞增下的競爭和壟斷的分析也是我們的一個困惑。我們不能簡單地認為市場從長期看會解決這個問題的,然后完全交給市場去處理。規(guī)模遞增并不是數據市場的獨有特點,軟件業(yè)也有這個特點,但開源模式限制了規(guī)模遞增導致的大者愈大,因此壟斷問題沒有走向極端。雖然領先者有規(guī)模遞增的能力,但是開源之后,更多的開發(fā)者和應用市場出現,目前沒有導致規(guī)模遞增一定會致使大者越大、強者越強的局面出現。
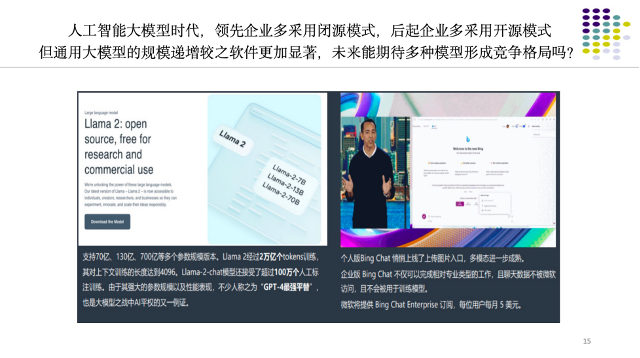
對于大模型,我們能期待這個趨勢出現嗎?仍是未知。如果理論不能有預測性的話,就沒有價值。現在我們的知識能夠想到 OpenAI 在 AI 時代,其產業(yè)組織、競爭壟斷的格局最后會不會避免走向極端?也是未知。所以這個問題對我們是一個很大的新挑戰(zhàn)。
關于公共數據
公共數據的性質有很多討論,有觀點認為數據本身具有公共品性質,公共數據又是政府掌握的數據,應該對社會開放。公共數據對公眾開放是國際共識。開放數據的定義是“公眾可獲取的、能夠被用戶完整觀測和使用的數據”。2009 年,美國的奧巴馬政府頒布了《開放政府指令》(US Open Government Directive);2018 年 12 月 24 日,美國國會通過《開放政府數據法案》,要求聯邦機構必須以“機器可讀”格式,即以方便公眾在智能手機或電腦上閱讀的數據格式,發(fā)布任何不涉及公眾隱私或國家安全的“非敏感”信息。例如,紐約市的政府及分支機構所擁有的數據必須對公眾實施開放,市民們使用這些信息不需要經過任何注冊、審批的繁瑣程序,使用數據也不受限制。2011 年,巴西、印尼、墨西哥、挪威、南非、菲律賓、英國和美國簽署了《開放數據聲明》,公共數據開放也是 2011 年成立的“開放政府合作伙伴”。迄今為止,全球已經有 75 個國家加入這一計劃。國內政府數據開放發(fā)展至今,發(fā)展和應用最好的主要還是地理位置信息的開放、公共設施的數據開放(圖書館、教育機構、公共wifi等)、涉及健康安全的數據開放(比如河流洪水水位、交通擁堵狀況、空氣指數等)、市場監(jiān)管數據開放(企業(yè)信息查詢、行政處罰查詢等)。這些信息現已可以通過多種途徑獲得。政府數據開放意義重大,但多年下來動力不夠是普遍問題。作為數據提供者的政府機構并不能從中直接得到經濟回報,相反承擔著泄露商業(yè)秘密和個人隱私的巨大風險,即便對數據采取“脫敏”處理也無法完全消除隱患。從道理上看,允許對數據開放并有一些收費也有合理性,例如有些原始數據不能直接開放共享,要做成數據產品;再如有些公共數據并不被廣大公民和市場主體所需要,是某些企業(yè)的運營需要。公共品是為廣大公民和市場主體服務的,對少數人服務“用者付費”這是公共品的基本原則。今后,要尋求免費開放(開放共享)與收費開放(開發(fā)利用)的平衡。“數據二十條”里的提法是:“推動用于公共治理、公益事業(yè)的公共數據有條件無償使用,探索用于產業(yè)發(fā)展、行業(yè)發(fā)展的公共數據有條件有償使用”。目前看,對公共數據有償開發(fā)開了一個口子以后,政府和相關公共企事業(yè)單位動力更強勁,行動更迅速。各地政府紛紛成立國有數據運營公司開展政府數據的授權運營,還可以搞二級合作商,獲取合理的收入,這是一個非常普遍的趨勢。政府大規(guī)模出售公共數據,公共品性質的數據轉化為商業(yè)化數據,需要學術理論給予分析和解釋,至少對公共品理論的發(fā)展提出了要求。總的來講,中國是一個數據生產大國和使用大國,我們是首先提出數據要素概念的國家,其中的實踐探索多元而豐富,期待學術界同仁共同努力,構建符合學術理論規(guī)范、包含數據實踐主要問題、體現中國數據發(fā)展特色的學術體系。文章來源:清華大學互聯網產業(yè)研究院
 AII微信公眾號
AII微信公眾號
 AII頭條號
AII頭條號